Research
My research encompasses automatic understanding of high-level informations in multimodal documents and multimodal interactions. My work lies at the frontier of natural language processing, spoken language processing, machine learning and more recently artificial vision. My objective is to enable computers to understand complex natural interaction situations between human beings. In order to reach that objective, I develop three complementary areas of research: semantic content analysis and modeling, multimodal system fusion, and rigorous evaluation of related technologies in realistic applications.
Students
- Manon Scholivet, 2017+, "Multilingual representations for NLP", ED-184
- Simone Fuscone, 2017+, "Linguistic Underpinnings of Conversational Interpersonal Dynamics", DOC2AMU
- Jeremy Auguste, 2016+, "Learning conversation representations", ANR DATCHA
- Sébastien Delecraz, 2015+, "Multimodal understanding", AMU-DGA
- Thibault Magallon, 2015+, "OCR and document structuring", CIFRE Numericompta
- Olivier Michalon, 2013-2017, "Semantic parsing of French", ANR ASFALDA
- Jérémie Tafforeau, 2013-2017, "Adaptation of NLP pipeline", FP7 SENSEI
- Jérémy Trione, 2013-2017, "Summarization of human-human conversations", FP7 SENSEI
Projects
PARSEME-FR: syntactic parsing and multiword expressions in French
- ANR project, 2015-2020
- http://parsemefr.lif.univ-mrs.fr
- Partners: LIF, LIGM, INRIA, LI, LIFO
Multiword expressions break the general hypothesis that words can be considered as basic units in natural language processing applications. In this project we tackle the definition, annotation, detection and integration of MWEs in French texts, in conjunction with the Parseme COST (http://typo.uni-konstanz.de/parseme).
HOMEOSTASIS: art and sciences

- http://pulsopulso.com
- Partners: LIF, PULSO
In this project, we explore jointly with the PULSO dance company how language interactions between humans and machines can fuel artistic creation. A first show, Homeostasis, showcases how failure in speech input capabilities can encourage artists to improvise and ensure continuity in the artistic creation process. More info can be found at http://pageperso.lif.univ-mrs.fr/~benoit.favre/homeostasis.
- Relevant papers
- Benoit Favre, Mickael Rouvier, Frédéric Béchet, Rocio Berenguer, "Speech Input for Live Performance: An Impromptu Dialogue Between the Computer and the Artist", International Workshop on Spoken Dialogue Systems (IWSDS), 2016
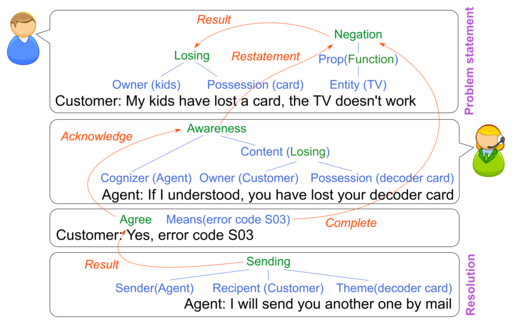
DATCHA: analysing customer care chats
- ANR project, 2015-2019
- http://datcha.lif.univ-mrs.fr
- Partners: LIF, IRIT, Orange
Current customer care analytics solutions are often limited to low-level analysis. In this project, we want to explore the relation between discourse and semantic analysis of customer care textual chats. Our hypothesis is that both components can be combined for better robustness. The work will be evaluated by Orange according to task-oriented metrics.
- Relevant papers
- Jeremy Auguste, Delphine Charlet, Géraldine Damnati, Benoit Favre, Frederic Bechet, "Evaluation automatique de la satisfaction client à partir de conversations de type « chat » par réseaux de neurones récurrents avec mécanisme d’attention.", TALN, 2018
- Benoit Favre, Frédéric Béchet, Géraldine Damnati, Delphine Charlet, "Apprentissage d’agents conversationnels pour la gestion de relations clients", 24e Conférence sur le Traitement Automatique des Langues Naturelles (TALN), 2017
- Elisabeth Godbert, Benoit Favre, "Détection de coréférences de bout en bout en français", 24e Conférence sur le Traitement Automatique des Langues Naturelles (TALN), 2017
- Arnaud Jeremy Auguste, Rey, Benoit Favre, "Evaluation of word embeddings against cognitive processes: primed reaction times in lexical decision and naming tasks", Proceedings of the 2nd Workshop on Evaluating Vector Space Representations for NLP, 2017
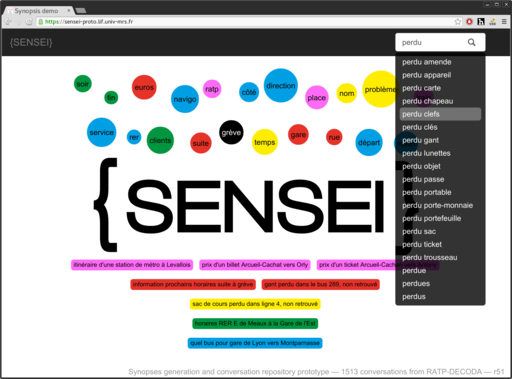
SENSEI: making sense of human-human interactions
- European Union FP7 project, 2013-2016
- http://www.sensei-conversations.eu
- Partners: LIF, U. Trento, U. Sheffield, U. Essex, Websays, Teleperformance.
The SENSEI project aims at leveraging natural language processing for structuring and summarizing human-human conversations. The project focuses on two use cases: call-centre conversations and comments to news articles on the web. For both use cases, we create NLP pipelines up to semantic and para-semantic analysis. Our group explores domain and cross-language adaptation with deep learning methods, as well as abstractive summarization approaches for conversations. The SENSEI project also strives to perform an ecological evaluation of the proposed technologies.
- Relevant papers
- Mickael Rouvier, Benoit Favre, "SENSEI-LIF at SemEval-2016 Task 4: Polarity embedding fusion for robust sentiment analysis.", SemEval@ NAACL-HLT, 2016
- Jeremie Tafforeau, Frederic Bechet, Thierry Artiere, Benoit Favre, "Joint syntactic and semantic analysis with a multitask Deep Learning Framework for Spoken Language Understanding", Interspeech, San Francisco (USA), 2016
- Jérémy Trione, Benoit Favre, Frédéric Béchet, "Beyond utterance extraction: summary recombination for speech summarization", Interspeech, San Francisco (USA), 2016
- Sebastien Delecraz, Frederic Bechet, Benoit Favre, Mickael Rouvier, "Fusion d'espaces de représentations multimodaux pour la reconnaissance du rôle du locuteur dans des documents télévisuels", Actes de la conférence JEP 2016, 2016
- Jérémy Trione, Benoit Favre, Frederic Bechet, "Détection de concepts pertinents pour le résumé automatique de conversations par recombinaison de patrons", Actes de la conférence TALN 2016, 2016
- G. Riccardi, F. Bechet, M. Danieli, B. Favre, R. Gaizauskas, U. Kruschwitz, M. Poesio, "The SENSEI Project: Making Sense of Human Conversations", Lecture Notes on Artificial Intelligence, pp. 10-33, 2016
- Adam Funk, Robert Gaizauskas, Benoit Favre, "A Document Repository for Social Media and Speech Conversations", Language Resources and Evaluation Conference (LREC), 2016
- Morena Danieli, Balamurali A R, Evgeny Stepanov, Benoit Favre, Frederic Bechet, Giuseppe Riccardi, "Summarizing Behaviours: An Experiment on the Annotation of Call-Centre Conversations", Language Resources and Evaluation Conference (LREC), 2016
- Balamurali A R, Frédéric Béchet, Benoit Favre, "CallAn: A Tool to Analyze Call Center Conversations", International Workshop on Spoken Dialogue Systems (IWSDS), 2016
- Jeremie Tafforeau, Frederic Bechet, Benoit Favre, Thierry Artieres, "Lexical embedding adaptation for open-domain spoken language understanding", NIPS Workshop on Spoken Language Understanding (SLUNIPS), 2015
- Mickael Rouvier, Sebastien Delecraz, Benoit Favre, Meriem Bendris, Frederic Bechet, "Multimodal Embedding Fusion for Robust Speaker Role Recognition in Video Broadcast", IEEE ASRU, 2015
- E. Stepanov, B. Favre, F. Alam, S. Chowdhury, K. Singla, J. Trione, F. Bechet, G. Riccardi, "Automatic Summarization of Call-Centre Conversations", IEEE ASRU Demo, 2015
- Jeremie Tafforeau, Thierry Artieres, Benoit Favre, Frederic Bechet, "Adapting lexical representation and OOV handling from written to spoken language with word embedding", Interspeech, 2015
- George Giannakopoulos, Jeff Kubina, John Conroy, Josef Steinberger, Benoit Favre, Mijail Kabadjov, Udo Kruschwitz, Massimo Poesio, "MultiLing 2015: Multilingual Summarization of Single and Multi-Documents, On-line Fora, and Call-center Conversations", Sigdial, 2015
- Benoit Favre, Evgeny Stepanov, Jérémy Trione, Frédéric Béchet, Giuseppe Riccardi, "Call Centre Conversation Summarization: A Pilot Task at Multiling 2015", Sigdial, 2015
- Jeremy Trione, Frederic Bechet, Benoit Favre, Alexis Nasr, "Rapid FrameNet annotation of spoken conversation transcripts", Joint ACL-ISO Workshop on Interoperable Semantic Annotation, 2015
ADNVideo: multimodal video recommendation
- Amidex project, 2014-2017
- http://www.kalyzee.com
- Partners: LIF, LSIS, Kalyzee
This project is a tech-transfer project towards industry. It looks into developing robust approaches for semantic analysis from videos on which to base recommendation algorithms. The application domain is advertisement recommendation on user-created videos. Technologies created in the PERCOL project are being ported to the platform developed by Kalizee.
- Relevant papers
- Mickael Rouvier, Benoit Favre, "Investigation of Speaker Embeddings for Cross-show Speaker Diarization", International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016
- Meriem Bendris, Delphine Charlet, Gregory Senay, MinYoung Kim, Benoit Favre, Mickael Rouvier, Frederic Bechet, Géraldine Damnati, "PERCOLATTE: A Multimodal Person Discovery System in TV Broadcast for the Medieval 2015 Evaluation Campaign", Mediaeval 2015 Multimedia Benchmark Workshop, Wurzen, Germany, 2015
- Mickael Rouvier, Pierre-Michel Bousquet, Benoit Favre, "Speaker diarization through speaker embeddings", EUSIPCO, 2015
ORFEO: annotated corpus of spoken and written French
- ANR project, 2012-2016
- http://www.projet-orfeo.fr
- Partners: LIF, LATTICE, MODYCO, ATILF, LORIA, CLLE-ERSS, ICAR
The ORFEO project aims at creating resources for supporting the next-level of humanities research based on French corpora. In this project, we have gathered a wide range of text and speech transcript corpora in French language, and harmonized existing annotations and trained NLP systems for generating missing or higher levels of annotations. The corpora will be accessible through various query mechanisms and annotations will be correctable in a wiki-like fashion. I am in particular in charge of sentence-like unit segmentation in speech corpora, and we also use the macaon platform for generating analyses up to syntactic parses.
- Relevant papers
- Alexis Nasr, Frederic Bechet, Benoit Favre, Thierry Bazillon, Jose Deulofeu, Andre Valli, "Automatically enriching spoken corpora with syntactic information for linguistic studies", LREC, 2014
ASFALDA: semantic analysis of French
- ANR project, 2012-2016
- https://sites.google.com/site/anrasfalda/
- Partners: LIF, Alpage, CEA, IRIT, LLF
The objective of the Asfalda project is to explore open-domain surface semantic analysis with the creation of French framenet full-text annotated corpora and parsers. We currently explore fast adaptation of parsers, exogenous data integration, and the relation between deep syntax and surface semantics for building better semantic parsers.
Past projects
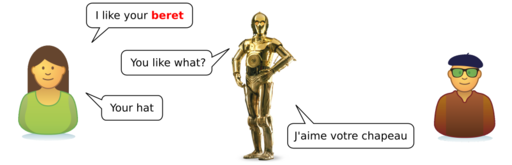
ThunderBOLT: speech-to-speech translation with clarification dialogs
- DARPA BOLT Project, 2012-2015
- http://www.sri.com/work/projects/broad-operational-language-technology-bolt-program
- Parters: LIF, SRI International, U. Washington, U. Rochester, U. Columbia
Typical speech-to-speech machine translation systems have a limited domain knowledge and static models. The mistake they make when transcribing and translating speech usually harms the conversation to a point of failure. In this project, we have proposed to enhance a speech-to-speech MT system with clarification dialogs which can recover system errors. ASR and MT errors are detected and characterized so that a dialog system can ask targeted questions in order to solicit clarifications from the user. These can then be integrated in the system knowledge in order to fix the system output and to learn how to prevent those mistakes in the future.
- Relevant papers
- Frederic Bechet, Benoit Favre, Mickael Rouvier, "Speech is silver, but silence is golden: improving speech-to-speech translation performance by slashing users input", Interspeech, 2015
- Michael Rouvier, Benoit Favre, Frederic Bechet, "Joint Decoding of Complementary Utterances", Spoken Languge Technologies (SLT), Lake Tahoe (USA), 2014
- Frederic Bechet, Alexis Nasr, Benoit Favre, "Adapting dependency parsing to spontaneous speech for open domain spoken language understanding", Interspeech, Singapore, 2014
- Frederic Bechet, Benoit Favre, Alexis Nasr, Mathieu Morey, "Retrieving the syntactic structure of erroneous ASR transcriptions for open-domain Spoken Language Understanding", ICASSP2014 - Speech and Language Processing (ICASSP2014 - SLTC), 2014
- Benoit Favre, Mickael Rouvier, Frederic Bechet, "Reranked aligners for interactive transcript correction", ICASSP2014 - Speech and Language Processing (ICASSP2014 - SLTC), 2014
- Frederic Bechet, Benoit Favre, "Asr Error Segment Localization for Spoken Recovery Strategy", IEEE International Conference in Acoustics, Speech and Signal Processing (ICASSP), Vancouver (Canada), 2013
- Necip Fazil Ayan, Arindam Mandal, Michael Frandsen, Jing Zheng, Peter Blasco, Andreas Kathol, Frederic Bechet, Benoit Favre, Alex Marin, Tom Kwiatkowski, Mari Ostendorf, Luke Zettlemoyer, Philipp Salletmayr, Julia Hirschberg, Svetlana Stoyanchev, "Can You Give Me Another Word for Hyperbaric?: Improving Speech Translation using Targeted Clarification Questions", IEEE International Conference in Acoustics, Speech and Signal Processing (ICASSP), Vancouver (Canada), 2013
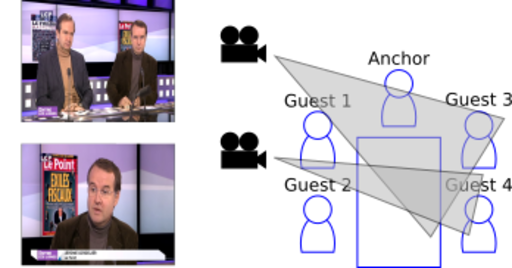
PERCOL: person recognition in broadcast videos
- ANR Project, 2011-2014
- https://sites.google.com/site/leprojetpercol
- Partners: LIF, Orange, LIA, LIFL
This project addresses the problem of person identification in videos for indexing and information retrieval applications. Since maintaining biometric models for face recognition and speaker identification for a large number of persons is not realistic, we have focused on acquiring identities on the fly using displayed and pronounced names, as well as role and scene analysis. These aspects enabled the PERCOL team to win the Defi Repere challenge.
- Relevant papers
- Frederic Bechet, Meriem Bendris, Delphine Charlet, Geraldine Damnati, Benoit Favre, Mickael Rouvier, Remi Auguste, Benjamin Bigot, Richard Dufour, Corinne Fredouille, Georges Linares, Jean Martinet, Gregory Senay, Pierre Trilly, "Identification de personnes dans des flux multimédia", CORIA, 2015
- Frederic Bechet, Meriem Bendris, Delphine Charlet, Geraldine Damnati, Benoit Favre, Mickael Rouvier, Remi Auguste, Benjamin Bigot, Richard Dufour, Corinne Fredouille, Georges Linares, Grégory Senay, Pierre Tirilly, Jean Martinet, "Multimodal understanding for person recognition in video broadcasts", Interspeech, Singapore, 2014
- Bendris Meriem, Delphine Charlet, Damnati Geraldine, Benoit Favre, Mickael Rouvier, "Scene understanding for identifying persons in TV shows: beyond face authentication", 12th International Workshop on Content-Based Multimedia Indexing (CBMI), Klagenfurt (Austria), 2014
- Meriem Bendris, Delphine Charlet, Benoit Favre, Geraldine Damnati, Rémi Auguste, "Multiple-View Constrained Clustering For Unsupervised Face Identification, In TV-Broadcast", ICASSP2014 - Image, Video, and Multidimensional Signal Processing, (ICASSP2014 - IVMSP), 2014
- Benoit Favre, Géraldine Damnati, Frederic Bechet, Meriem Bendris, Delphine Charlet, Rémi Auguste, Stéphane Ayache, Benjamin Bigot, Alexandre Delteil, Richard Dufour, Corinne Fredouille, Georges Linarès, Jean Martinet, Gregory Senay, Pierre Tirilly, "PERCOLI: a person identification system for the 2013 REPERE challenge", First Workshop on Speech, Language and Audio in Multimedia (SLAM), Marseille, France, 2013
- Meriem Bendris, Benoit Favre, Delphine Charlet, Geraldine Damnati, "Unsupervised Face Identification in TV Content using Audio-Visual Sources", 11th International Workshop on Content-Based Multimedia Indexing (CBMI), Veszprém (Hungary), 2013
- Frederic Bechet, Benoit Favre, Geraldine Damnati, "Detecting Person Presence in TV Shows with Linguistic and Structural Features", IEEE International Conference in Acoustics, Speech and Signal Processing (ICASSP), Kyoto (Japan), 2012
DECODA: call-centre conversation analysis
- ANR Project, 2010-2013
- http://decoda.univ-avignon.fr/
- Partners: LIF, LIA, RATP, SONEAR
This project focuses on speech analytics from call centre recordings.
- Relevant papers
- Thierry Bazillon, Melanie Delplano, Frederic Bechet, Alexis Nasr, Benoit Favre, "Syntactic annotation of spontaneous speech: application to call-center conversation data", LREC'12, Istambul, Turkey, 2012
- Liva Ralaivola, Benoit Favre, Pierre Gotab, Frédéric Béchet, Géraldine Damnati, "Applying Multiclass Bandit algorithms to call-type classification", IEEE Automatic Speech Recognition and Understanding Workshop (ASRU'11), 2011
SEQUOIA: syntactic parsing of French
- ANR Project, 2009-2011
- https://sites.google.com/site/anrsequoia/home
- Partners: LIF, Alpage, LIA, LaLIC
While syntactic parsing has become a basic building block in NLP pipelines, this project aimed at bringing to French the benefits from latest advances in statistical parsing.
- Relevant papers
- Joseph Le Roux, Seyed Abolghasem Benoit Favre, Alexis Nasr, Mirroshandel, "Generative Constituent Parsing and Discriminative Dependency Reranking: Experiments on English and French", SP-SEM-MRL 2012, 2012
- A. Nasr, F. Béchet, J.F. Rey, B. Favre, J. Le Roux, "MACAON: an NLP tool suite for processing word lattices", Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: Systems Demonstrations, 2011
- Joseph Le Roux, Benoit Favre, Seyed Abolghasem Mirroshandel, Alexis Nasr, "Modèles génératif et discriminant en analyse syntaxique : expériences sur le corpus arboré de Paris 7", TALN'11, Montpellier (France), 2011
PORTMEDIA: robustness, portability of semantic parsing in dialog systems
- ANR Project, 2009-2012
- http://www.port-media.org
- Partners: LIA, LIG, LIUM, LORIA, ELDA
This project addressed the problem of porting dialog systems across languages or domains with minimal efforts. I joint this project while on postdoc at LIUM, and worked on concept detection and ASR.
- Relevant papers
- Fabrice Lefèvre, Djamel Mostefa, Laurent Besacier, Yannick Estève, Matthieu Quignard, Nathalie Camelin, Benoit Favre, Bassam Jabaian, Lina Rojas-Barahona, "Leveraging study of robustness and portability of spoken language understanding systems across languages and domains: the PortMedia corpora", LREC'12, Istambul, Turkey, 2012
- Fabrice Lefèvre, Djamel Mostefa, Laurent Besacier, Yannick Estève, Matthieu Quignard, Nathalie Camelin, Benoit Favre, Bassam Jabaian, Lina Rojas-Barahona, "Robustesse et portabilités multilingue et multi-domaines des systèmes de compréhension de la parole : les corpus du projet PortMedia (Robustness and portability of spoken language understanding systems among languages and domains : the PORTMEDIA project) [in French]", Actes de la conférence conjointe JEP-TALN-RECITAL 2012, volume 1: JEP, 2012
- Richard Dufour, Benoit Favre, "Semi-supervised Part-of-speech Tagging in Speech Applications", Interspeech, Tokyo (Japan), 2010
CALO: cognitive assistant that learns and organizes
- DARPA PAL program, 2003-2008
- https://en.wikipedia.org/wiki/CALO
- Partners: ICSI, SRI International...
The objective of the CALO project was to create an intelligent organizer that could help with meetings, documents, etc. I paricipated to this project while at ICSI and mainly worked on meeting summarization.
- Relevant papers
- Gokhan Tur, Andreas Stolcke, Lynn Voss, John Dowding, Benoit Favre, Raquel Fernandez, Matthew Frampton, Michael Frandsen, Clint Frederickson, Martin Graciarena, Dilek Hakkani-Tür, Donald Kintzing, Kyle Leveque, Shane Mason, John Niekrasz, Stanley Peters, Matthew Purver, Korbinian Riedhammer, Elizabeth Shriberg, Jing Tien, Dimitra Vergyri, Fan Yang, "The CALO Meeting Assistant System", IEEE Transactions on Audio, Speech and Language Processing, 2010
- Gokhan Tur, Andreas Stolcke, Lynn Voss, John Dowding, Benoit Favre, Raquel Fernandez, Matthew Frampton, Michael Frandsen, Clint Frederickson, Martin Graciarena, Dilek Hakkani-Tür, Donald Kintzing, Kyle Leveque, Shane Mason, John Niekrasz, Stanley Peters, Matthew Purver, Korbinian Riedhammer, Elizabeth Shriberg, Jing Tien, Dimitra Vergyri, Fan Yang, "The CALO Meeting Speech Recognition and Understanding System", Spoken Languge Technologies (SLT), Goa (India), 2008
NightinGALE: distillation from multilingual, multigenre speech and text
- DARPA GALE Project, 2005-2010
- http://www.speech.sri.com/projects/GALE
- Partners: ICSI, SRI International, U. Columbia, U. Washington, NYU...
The GALE project aimed at accurate information extraction from both broadcast news recordings and forum texts in English, Arabic and Chinese. I contributed to the NightinGALE team through sentence segmentation and punctuation detection in speech.
- Relevant papers
- Dilek Hakkani-Tür, Gokhan Tur, Benoit Favre, Elizabeth Shriberg, "Finding the Structure of Documents", Multilingual natural language processing applications, 2011
- Elizabeth Shriberg, Benoit Favre, James Fung, Dilek Hakkani-Tür, Sébastien Cuendet, "Prosodic Similarities of Dialog Act Boundaries Across Speaking Styles", Language and Lingusitics Monograph Series: Linguistic Patterns in Spontaneous Speech, pp. 213-239, 2009
- Umit Guz, Benoit Favre, Dilek Hakkani-Tür, Gokhan Tur, "Generative and Discriminative Methods using Morphological Information for Sentence Segmentation of Turkish", IEEE Transactions on Audio, Speech and Language Processing, Special Section on Processing Morphologically Rich Languages, pp. 895-903, 2009
- Mari Ostendorf, Benoit Favre, Ralph Grishman, Dilek Hakkani-Tur, Mary Harper, Dustin Hillard, Julia B. Hirschberg, Heng Ji, Jeremy G. Kahn, Yang Liu, Evgeny Matusov, Hermann Ney, Elizabeth Shriberg, Wen Wang, Chuck Wooters, "Speech segmentation and spoken document processing", Signal Processing Magazine, IEEE, pp. 59-69, 2008
Last updated on 2023-06-28